L’expérience centrale de Launch consiste à tester différentes entrées du job, comme des hyperparamètres et des jeux de données, puis à acheminer ces jobs vers le matériel approprié. Après avoir créé un job, des utilisateurs autres que l’auteur original peuvent ajuster ces entrées via l’interface utilisateur W&B ou le CLI. Pour savoir comment définir les entrées d’un job lors du lancement depuis le CLI ou l’interface utilisateur, voir le guide Mettre des jobs en file d’attente. Ce guide explique comment contrôler par programmation quelles entrées vous pouvez ajuster pour un job, afin de n’exposer que les paramètres que vous souhaitez permettre aux utilisateurs finaux de modifier. Par défaut, les jobs W&B capturent l’intégralité deDocumentation Index
Fetch the complete documentation index at: https://wb-21fd5541-docs-2661.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Run.config comme entrées du job, mais le SDK Launch fournit une fonction pour contrôler certaines clés de la configuration du run ou pour spécifier des fichiers JSON ou YAML comme entrées.
Les fonctions du SDK Launch nécessitent
wandb-core. Pour plus d’informations, voir le fichier wandb-core README.Reconfigurer l’objet Run
Run renvoyé par wandb.init() dans un job. Utilisez le SDK Launch pour personnaliser les parties de l’objet Run.config que vous pouvez reconfigurer au lancement du job, afin de masquer les paramètres internes tout en exposant les paramètres importants pour les utilisateurs finaux.
launch.manage_wandb_config() configure le job pour qu’il accepte des valeurs d’entrée pour l’objet Run.config. Les options facultatives include et exclude prennent des préfixes de chemin au sein de l’objet de configuration imbriqué. C’est utile si, par exemple, un job utilise une bibliothèque dont vous ne souhaitez pas exposer les options aux utilisateurs finaux.
Si vous fournissez des préfixes include, seuls les chemins de la configuration qui correspondent à un préfixe include acceptent des valeurs d’entrée. Si vous fournissez des préfixes exclude, les chemins correspondant à la liste exclude sont exclus des valeurs d’entrée. Si un chemin correspond à la fois à un préfixe include et à un préfixe exclude, le préfixe exclude est prioritaire.
Dans l’exemple précédent, le chemin ["trainer.private"] exclut la clé private de l’objet trainer, et le chemin ["trainer"] exclut toutes les clés qui ne se trouvent pas sous l’objet trainer.
Utilisez un
. précédé d’un caractère d’échappement \ pour exclure les clés dont le nom contient un ..Par exemple, r"trainer\.private" exclut la clé trainer.private plutôt que la clé private sous l’objet trainer.Le préfixe r dans l’exemple précédent désigne une chaîne brute.trainer.
Accéder aux entrées de configuration du run
Run.config. Le Run renvoyé par wandb.init() dans le code du job a automatiquement les valeurs des entrées définies. Pour charger les valeurs d’entrée de la configuration du run à n’importe quel endroit dans le code du job, utilisez launch.load_wandb_config() :
Reconfigurer un fichier
Sweeps on Launch ne prend pas en charge l’utilisation d’entrées du fichier de configuration comme paramètres de balayage. Les paramètres de balayage doivent être contrôlés via l’objet
Run.config.launch.manage_config_file() pour ajouter un fichier de configuration comme entrée du job Launch, ce qui vous permet de modifier les valeurs qu’il contient au moment de lancer le job.
Par défaut, aucune entrée de configuration du run n’est capturée si vous utilisez launch.manage_config_file(). L’appel à launch.manage_wandb_config() remplace ce comportement.
Prenez l’exemple suivant :
config.yaml situé dans le même répertoire :
launch.manage_config_file() ajoute le fichier config.yaml comme entrée du job, ce qui le rend reconfigurable lors d’un lancement depuis la CLI ou l’interface utilisateur de W&B.
Utilisez les arguments nommés include et exclude pour filtrer les clés d’entrée acceptées du fichier de configuration, de la même manière que launch.manage_wandb_config().
Accéder aux entrées du fichier de configuration
launch.manage_config_file() dans un run créé par Launch, launch met à jour le contenu du fichier de configuration avec les valeurs d’entrée. Le fichier de configuration mis à jour est disponible dans l’environnement du job.
Personnaliser l’interface du volet de lancement d’un job
launch.manage_wandb_config() ou launch.manage_config_file(). Le schéma peut être soit un dict Python au format JSON Schema, soit une classe de modèle Pydantic.
- Schéma JSON
- Modèle Pydantic
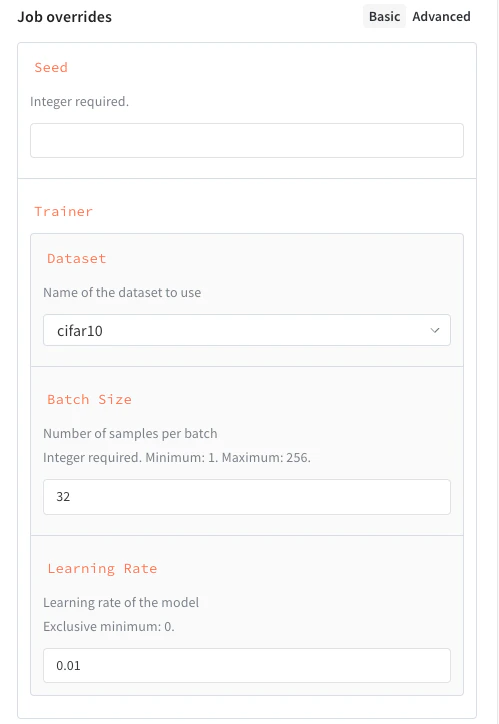
L’exemple suivant montre un schéma avec les propriétés suivantes :De manière générale, les attributs JSON Schema suivants sont pris en charge :
seed, un entier.trainer, un dictionnaire avec certaines clés spécifiées :trainer.learning_rate, un flottant qui doit être supérieur à zéro.trainer.batch_size, un entier qui doit être égal à 16, 64 ou 256.trainer.dataset, une chaîne qui doit être soitcifar10, soitcifar100.
| Attribut | Requis | Notes |
|---|---|---|
type | Oui | Doit être l’un de number, integer, string ou object |
title | Non | Remplace le nom d’affichage de la propriété |
description | Non | Fournit le texte d’aide de la propriété |
enum | Non | Crée une liste déroulante au lieu d’un champ de texte libre |
minimum | Non | Autorisé uniquement si type vaut number ou integer |
maximum | Non | Autorisé uniquement si type vaut number ou integer |
exclusiveMinimum | Non | Autorisé uniquement si type vaut number ou integer |
exclusiveMaximum | Non | Autorisé uniquement si type vaut number ou integer |
properties | Non | Si type vaut object, définit des configurations imbriquées |