Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-docs-2661.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Les embeddings représentent des objets tels que des personnes, des images, des publications ou des mots à l’aide d’une liste de nombres, parfois appelée vecteur. Dans les cas d’usage en machine learning et en science des données, vous pouvez générer des embeddings à l’aide de différentes approches dans un large éventail d’applications. Cette page suppose que vous connaissez déjà les embeddings et que vous souhaitez les analyser visuellement dans W&B.
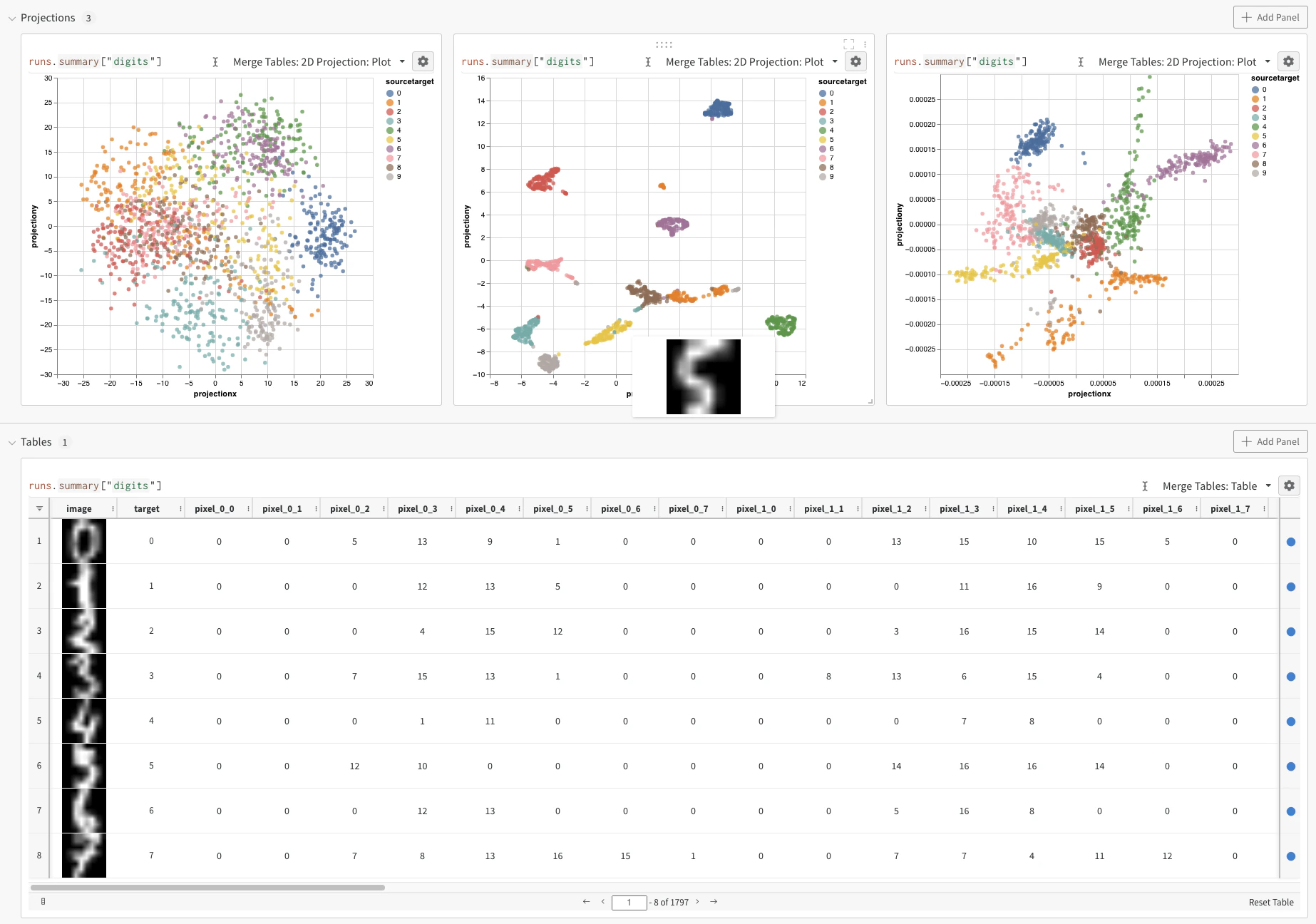
Ce guide vous montre comment journaliser des embeddings dans W&B et utiliser l’Embedding Projector pour les représenter sur un plan 2D avec des algorithmes de réduction de dimensionnalité tels que PCA, UMAP et t-SNE. Visualiser les embeddings de cette manière vous aide à explorer des clusters, à examiner les relations entre les points de données et à vérifier que vos embeddings capturent bien la structure attendue.
Les ressources suivantes montrent l’Embedding Projector en action avant de l’essayer vous-même :
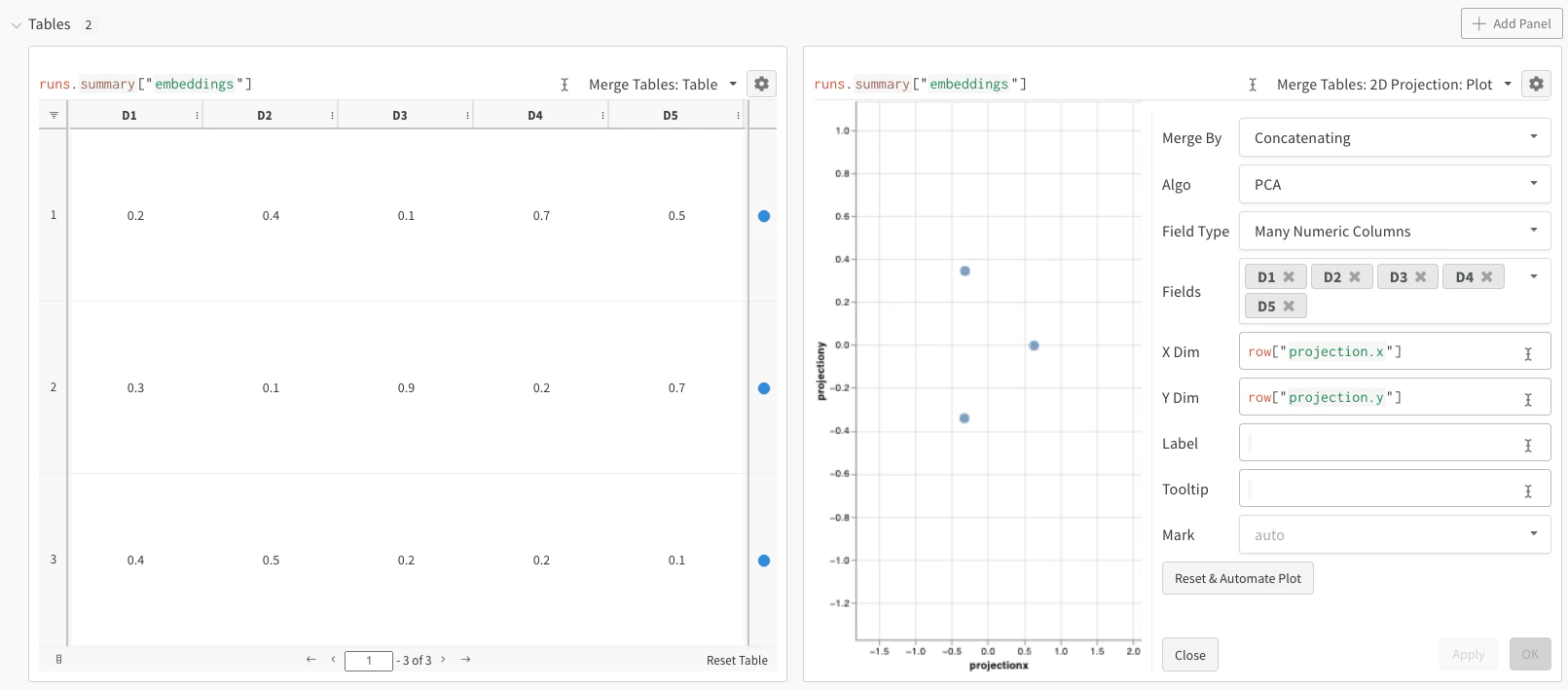
Cet exemple minimal montre le minimum de code nécessaire pour journaliser des embeddings et les visualiser dans le projecteur. W&B vous permet de journaliser des embeddings à l’aide de la classe wandb.Table. Considérez l’exemple suivant de trois embeddings, chacun composé de cinq dimensions :
import wandb
with wandb.init(project="embedding_tutorial") as run:
embeddings = [
# D1 D2 D3 D4 D5
[0.2, 0.4, 0.1, 0.7, 0.5], # embedding 1
[0.3, 0.1, 0.9, 0.2, 0.7], # embedding 2
[0.4, 0.5, 0.2, 0.2, 0.1], # embedding 3
]
run.log(
{"embeddings": wandb.Table(columns=["D1", "D2", "D3", "D4", "D5"], data=embeddings)}
)
run.finish()
import wandb
from sklearn.datasets import load_digits
with wandb.init(project="embedding_tutorial") as run:
# Charger le jeu de données
ds = load_digits(as_frame=True)
df = ds.data
# Créer une colonne "target"
df["target"] = ds.target.astype(str)
cols = df.columns.tolist()
df = df[cols[-1:] + cols[:-1]]
# Créer une colonne "image"
df["image"] = df.apply(
lambda row: wandb.Image(row[1:].values.reshape(8, 8) / 16.0), axis=1
)
cols = df.columns.tolist()
df = df[cols[-1:] + cols[:-1]]
run.log({"digits": df})
Options de journalisation
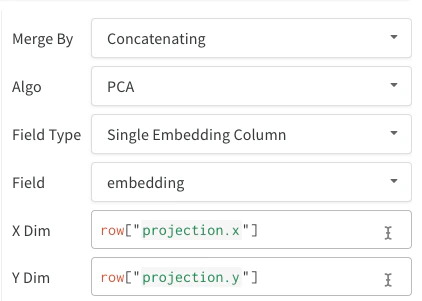
- Colonne d’embedding unique : Souvent, vos données sont déjà dans un format matriciel. Dans ce cas, vous pouvez créer une seule colonne d’embedding, où le type des valeurs des cellules peut être
list[int], list[float] ou np.ndarray.
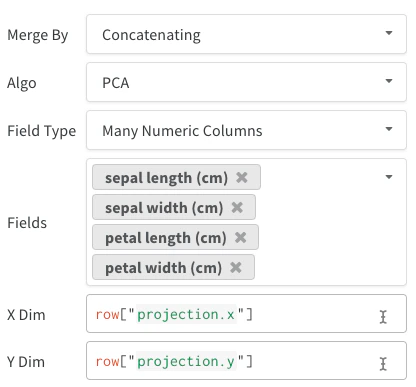
- Plusieurs colonnes numériques : Les deux exemples précédents utilisent cette approche et créent une colonne pour chaque dimension. W&B accepte des
int ou float Python dans les cellules.
Comme pour tous les tableaux, vous disposez de plusieurs options pour construire le tableau :
- Directement à partir d’un dataframe avec
wandb.Table(dataframe=df).
- Directement à partir d’une liste de données avec
wandb.Table(data=[...], columns=[...]).
- Construisez le tableau de façon incrémentielle, ligne par ligne (idéal si vous avez une boucle dans votre code). Ajoutez des lignes à votre tableau avec
table.add_data(...).
- Ajoutez une colonne d’embedding à votre tableau (idéal si vous avez une liste de prédictions sous forme d’embeddings) :
table.add_col("col_name", ...).
- Ajoutez une colonne calculée (idéal si vous avez une fonction ou un modèle à appliquer à votre tableau) :
table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)}).
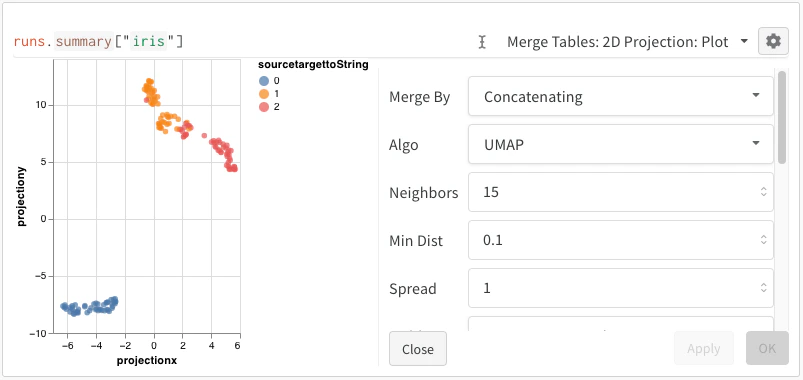
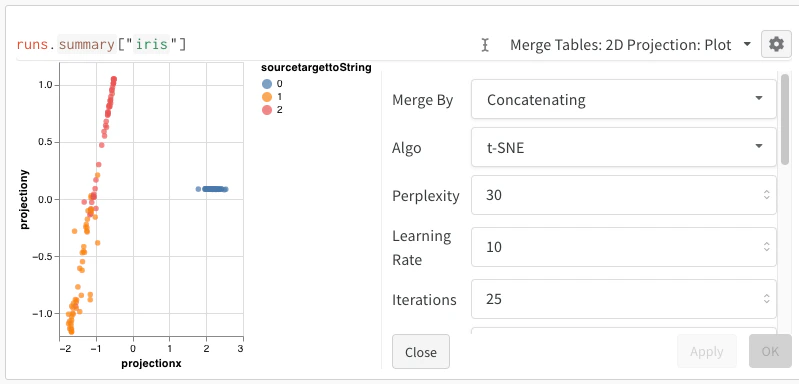
Après avoir journalisé vos embeddings, vous pouvez ajuster la façon dont ils sont projetés et affichés. Après avoir sélectionné 2D Projection, vous pouvez cliquer sur l’icône d’engrenage pour modifier les paramètres de rendu. En plus de sélectionner les colonnes souhaitées (voir les sections précédentes), vous pouvez choisir l’algorithme voulu (ainsi que les paramètres souhaités). Les images suivantes montrent les paramètres d’UMAP et de t-SNE.
W&B sous-échantillonne un sous-ensemble aléatoire de 1 000 lignes et 50 dimensions pour les trois algorithmes.