Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-docs-2661.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
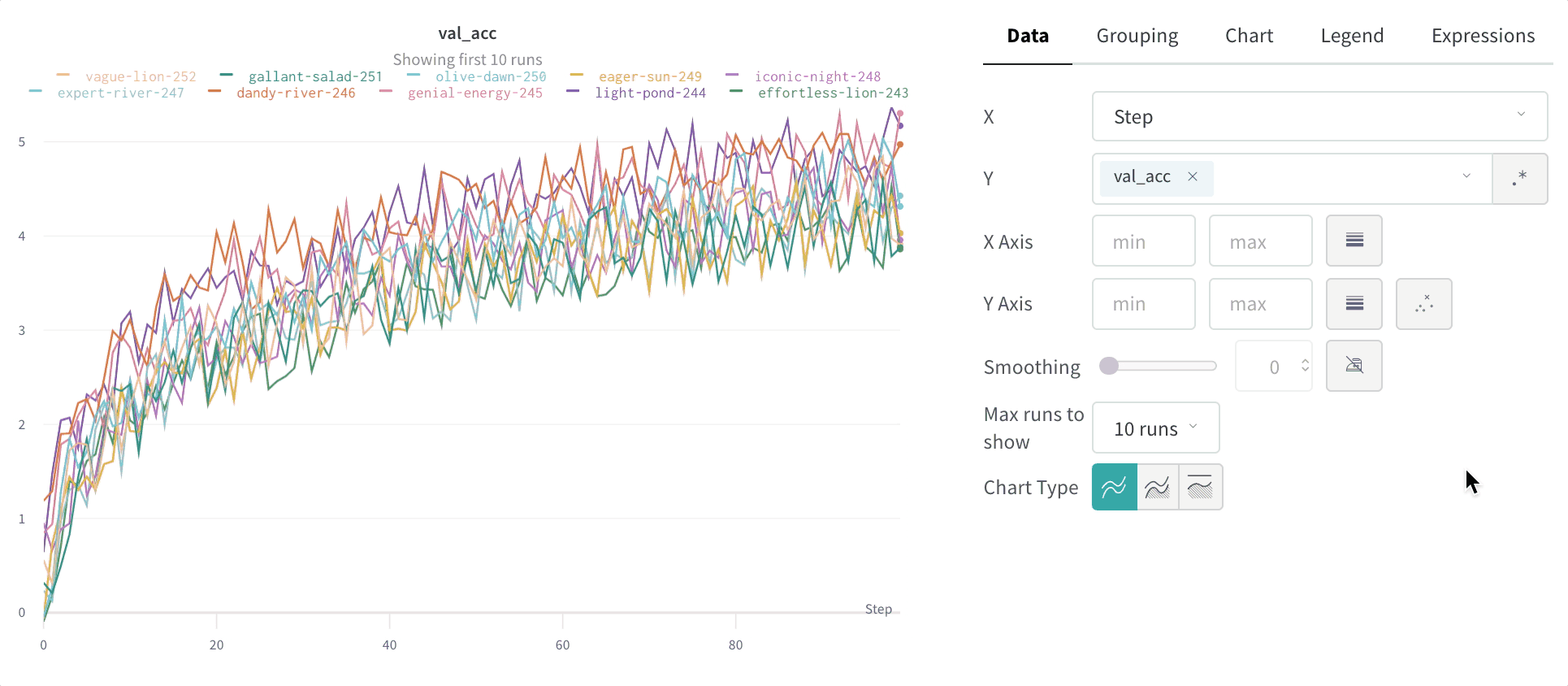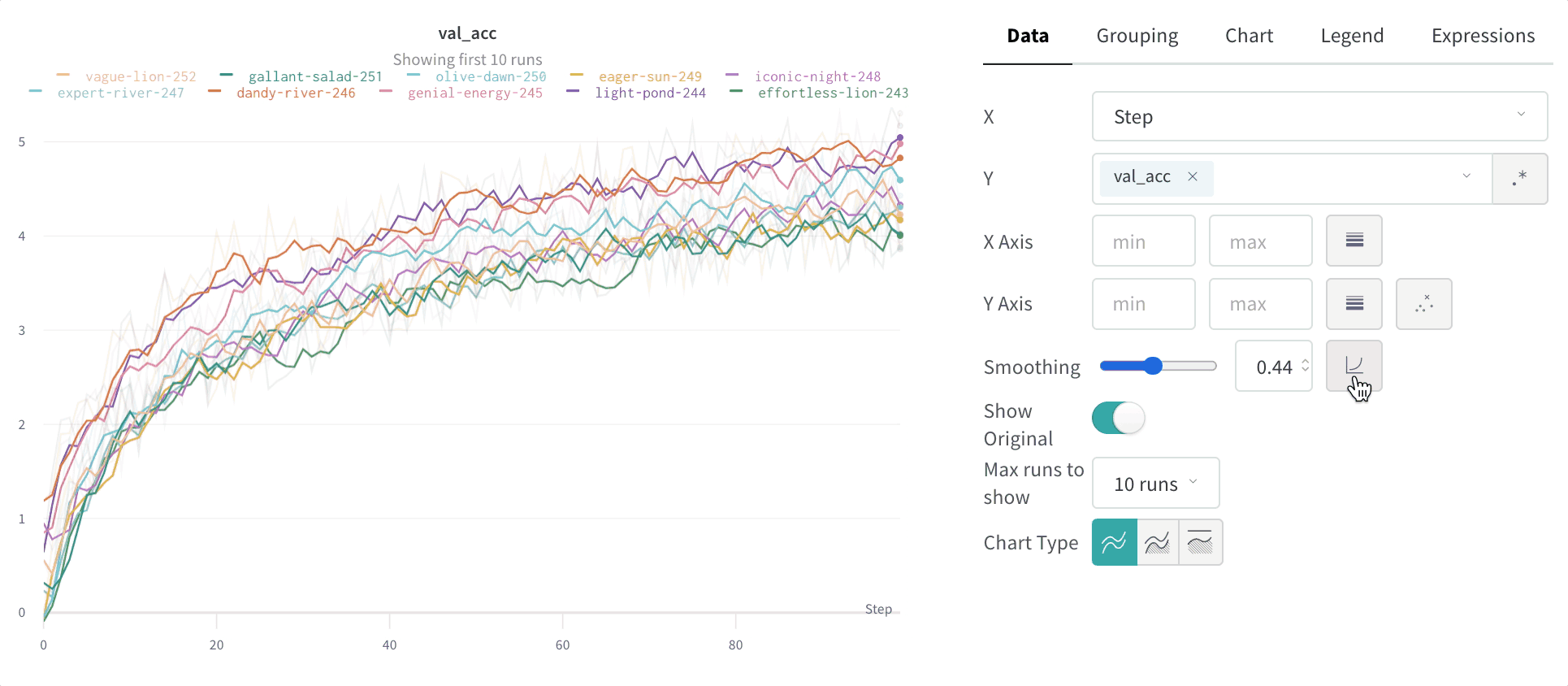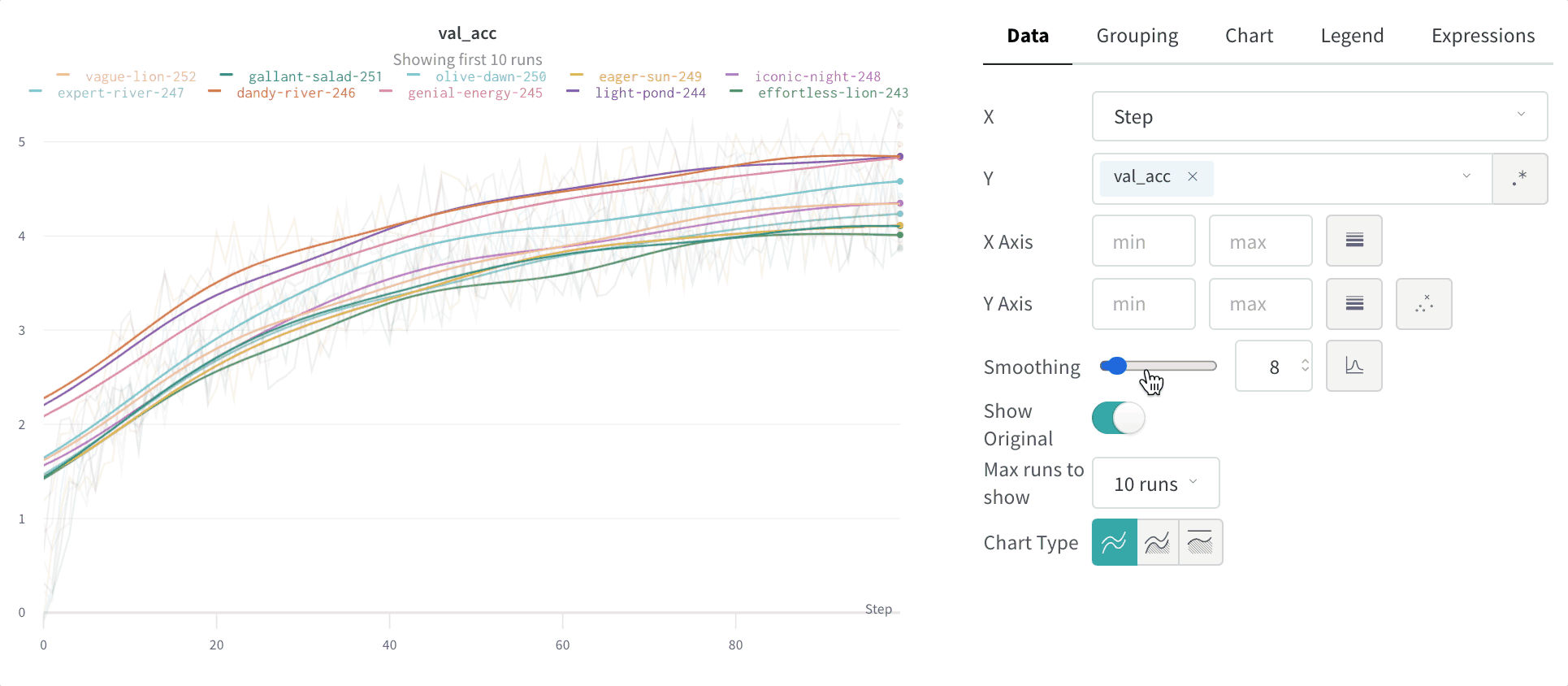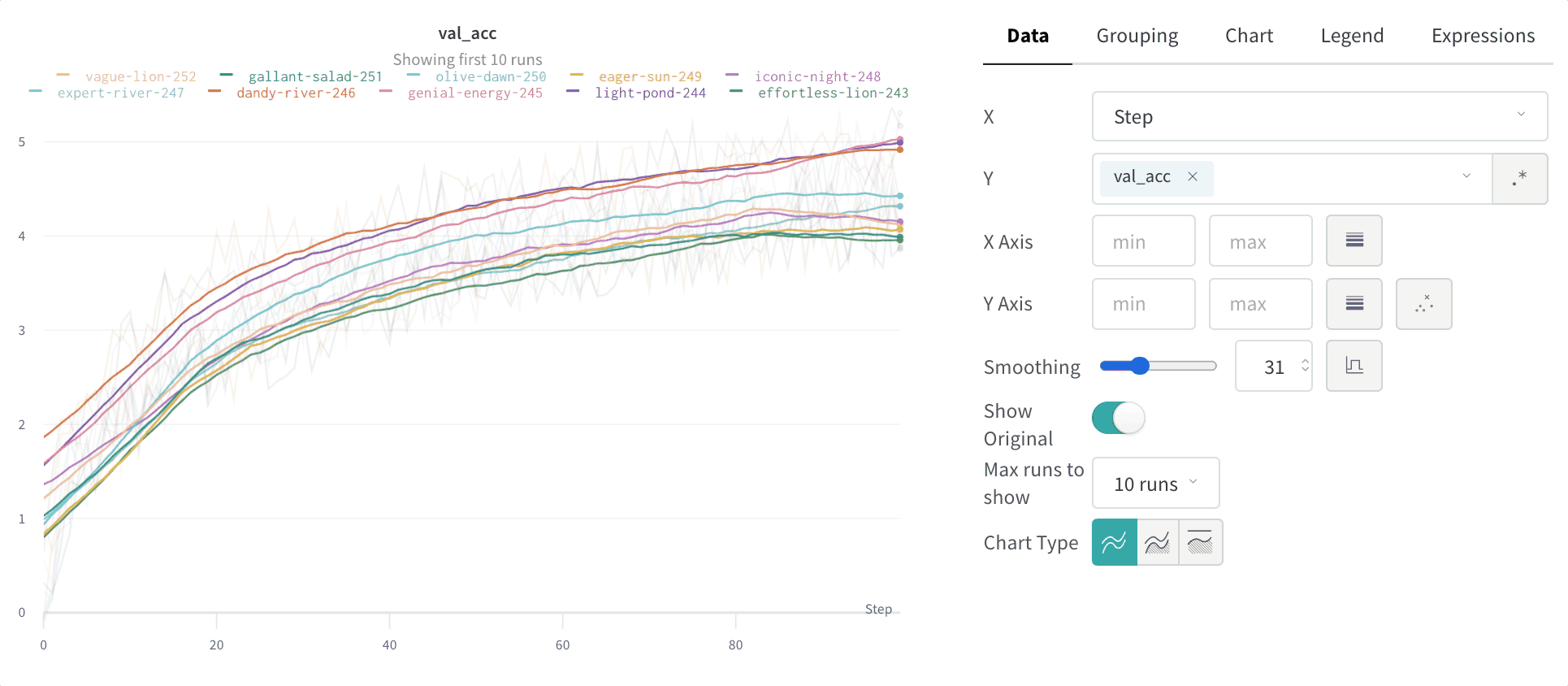
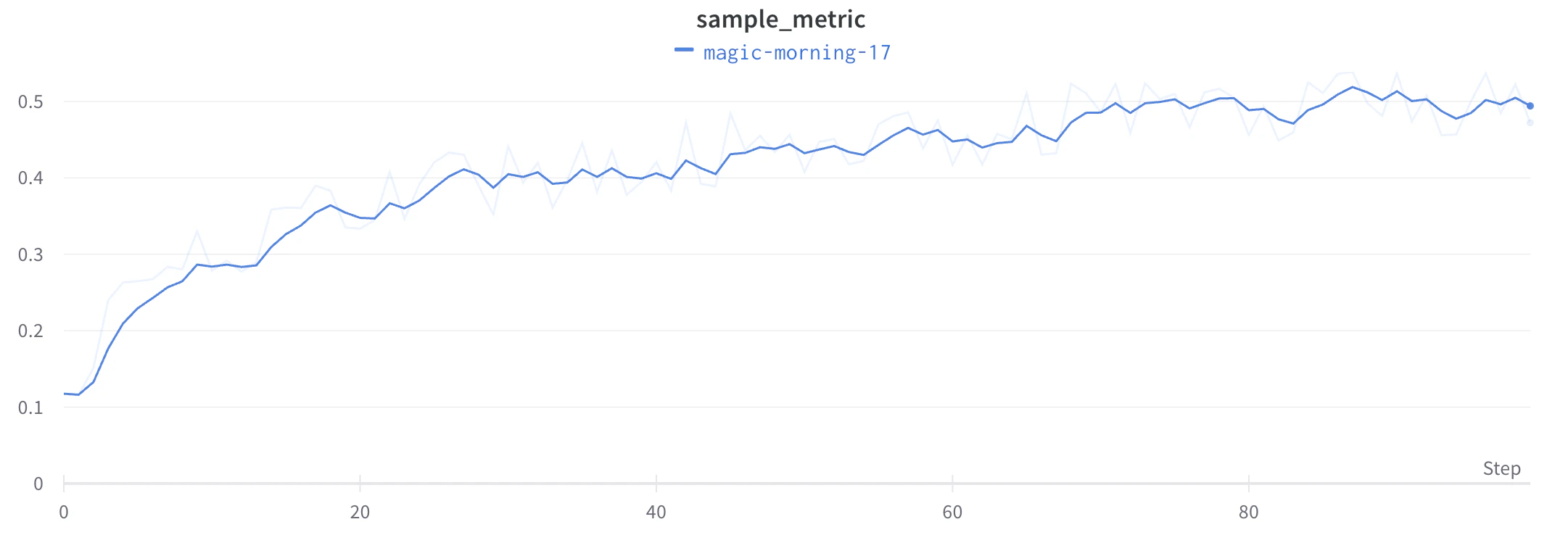
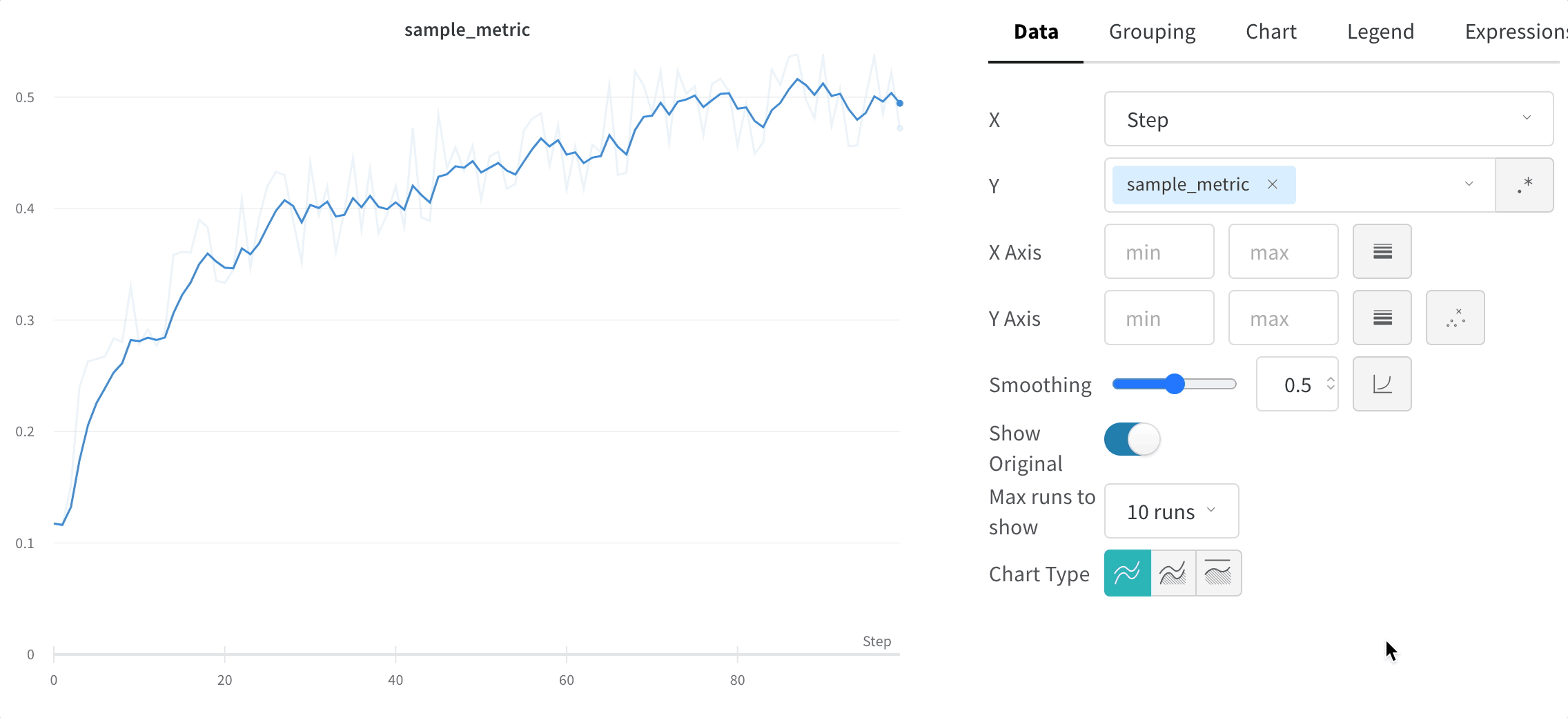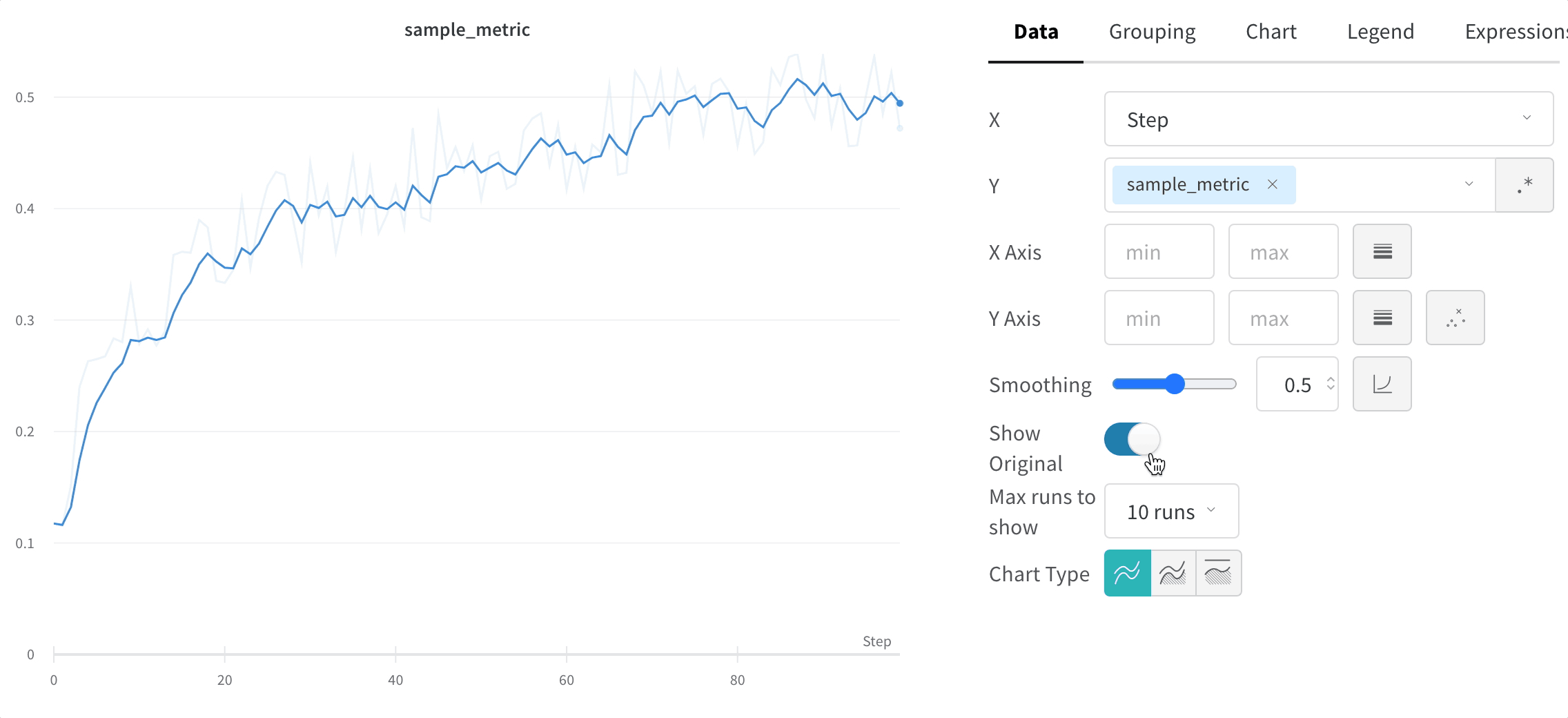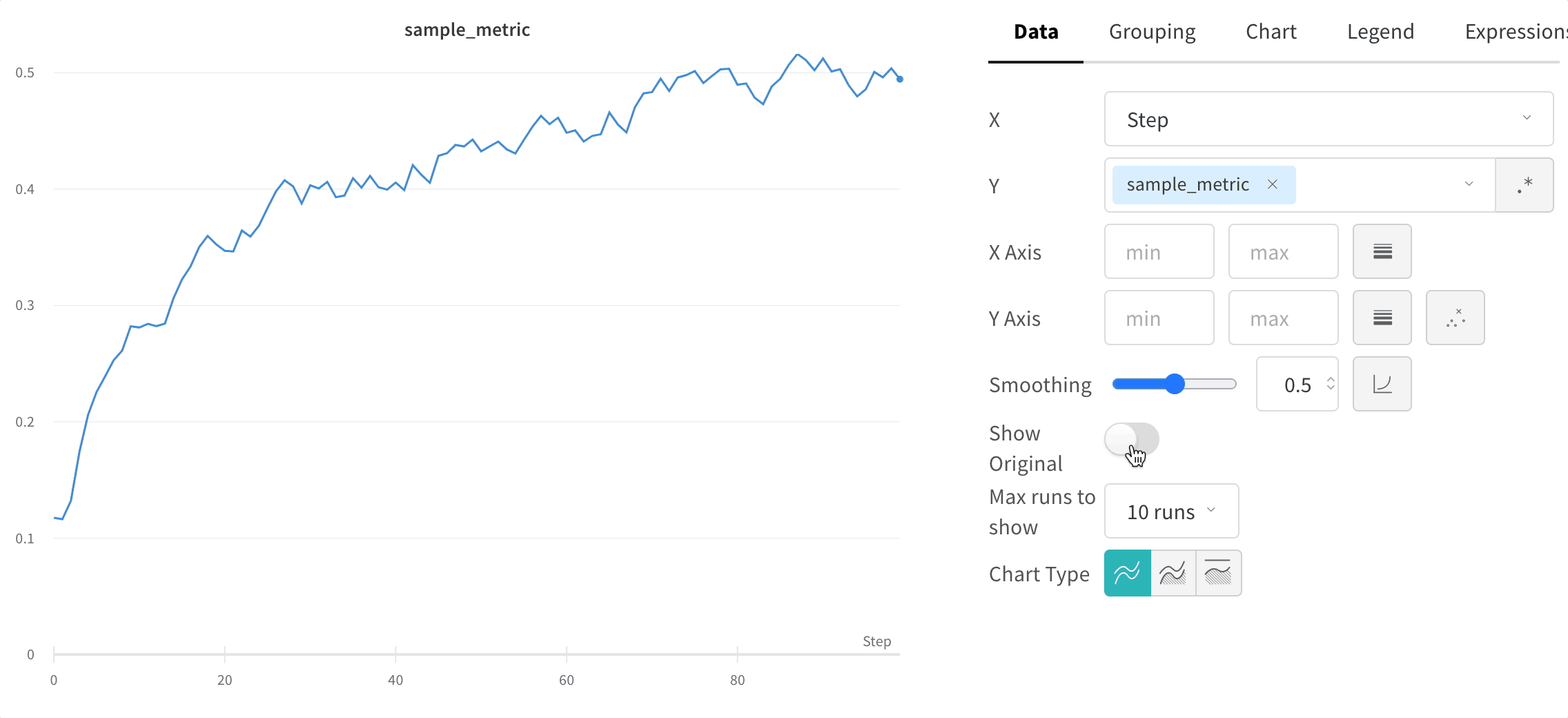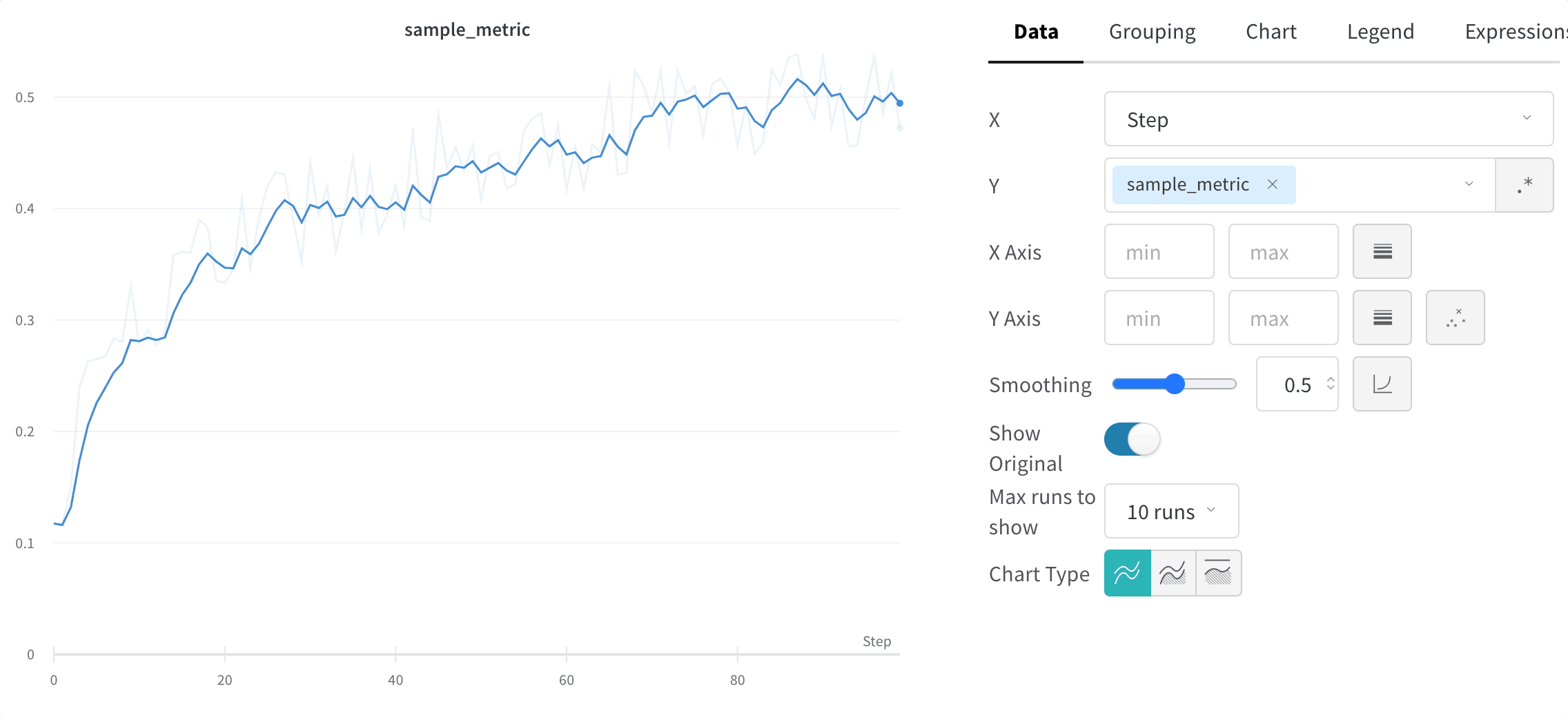
Le lissage vous aide à repérer les tendances dans des graphiques en courbes bruités en réduisant les variations d’un point à l’autre, ce qui rend le signal sous-jacent plus facile à lire. Cette page décrit les algorithmes de lissage que W&B prend en charge, dans quels cas chacun est le plus utile, et comment contrôler si les données d’origine restent visibles.
W&B prend en charge plusieurs types de lissage :
Pour voir ces algorithmes appliqués à des données réelles, consultez ce rapport W&B interactif.
lissage par moyenne mobile exponentielle pondérée par le temps (TWEMA) (par défaut)
y par unité de plage sur l’axe X). Cela permet d’obtenir un lissage cohérent lors de l’affichage simultané de plusieurs courbes aux caractéristiques différentes.
L’exemple de code suivant montre comment cela fonctionne en interne :
const smoothingWeight = Math.min(Math.sqrt(smoothingParam || 0), 0.999);
let lastY = yValues.length > 0 ? 0 : NaN;
let debiasWeight = 0;
return yValues.map((yPoint, index) => {
const prevX = index > 0 ? index - 1 : 0;
// VIEWPORT_SCALE met le résultat à l'échelle de la plage de l'axe X du graphique
const changeInX =
((xValues[index] - xValues[prevX]) / rangeOfX) * VIEWPORT_SCALE;
const smoothingWeightAdj = Math.pow(smoothingWeight, changeInX);
lastY = lastY * smoothingWeightAdj + yPoint;
debiasWeight = debiasWeight * smoothingWeightAdj + 1;
return lastY / debiasWeight;
});
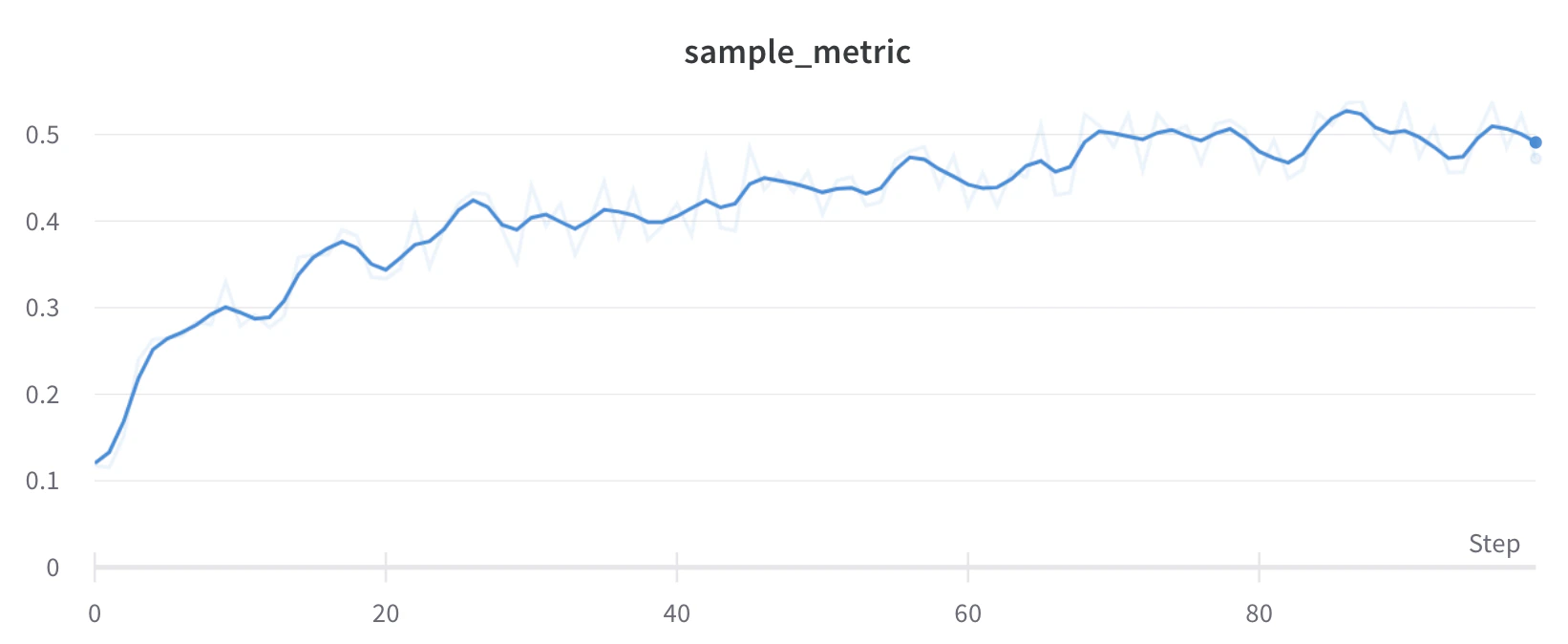
x en entrée, en se basant sur les points qui la précèdent et la suivent.
Pour voir cet algorithme appliqué à des données en direct, voir la section sur le lissage gaussien du rapport W&B interactif.
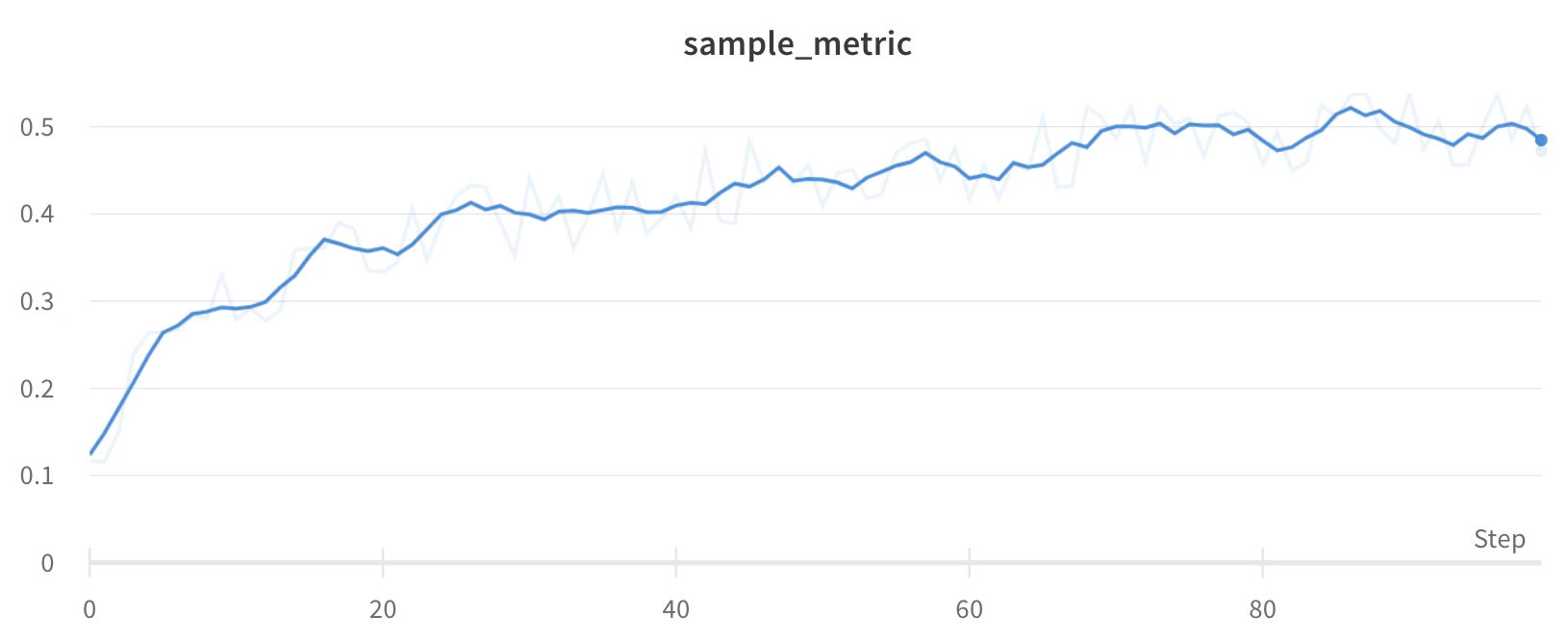
Lissage par moyenne glissante
x donnée. Voir « Boxcar Filter » sur Wikipedia. Le paramètre sélectionné pour la moyenne glissante indique le nombre de points à prendre en compte dans la moyenne mobile.
Si vos points sont espacés de manière irrégulière sur l’axe X, utilisez plutôt le lissage gaussien, car une fenêtre de largeur fixe peut produire des moyennes trompeuses lorsque la densité des points varie.
Pour voir cet algorithme appliqué à des données en temps réel, consultez la section sur la moyenne glissante du rapport W&B interactif.
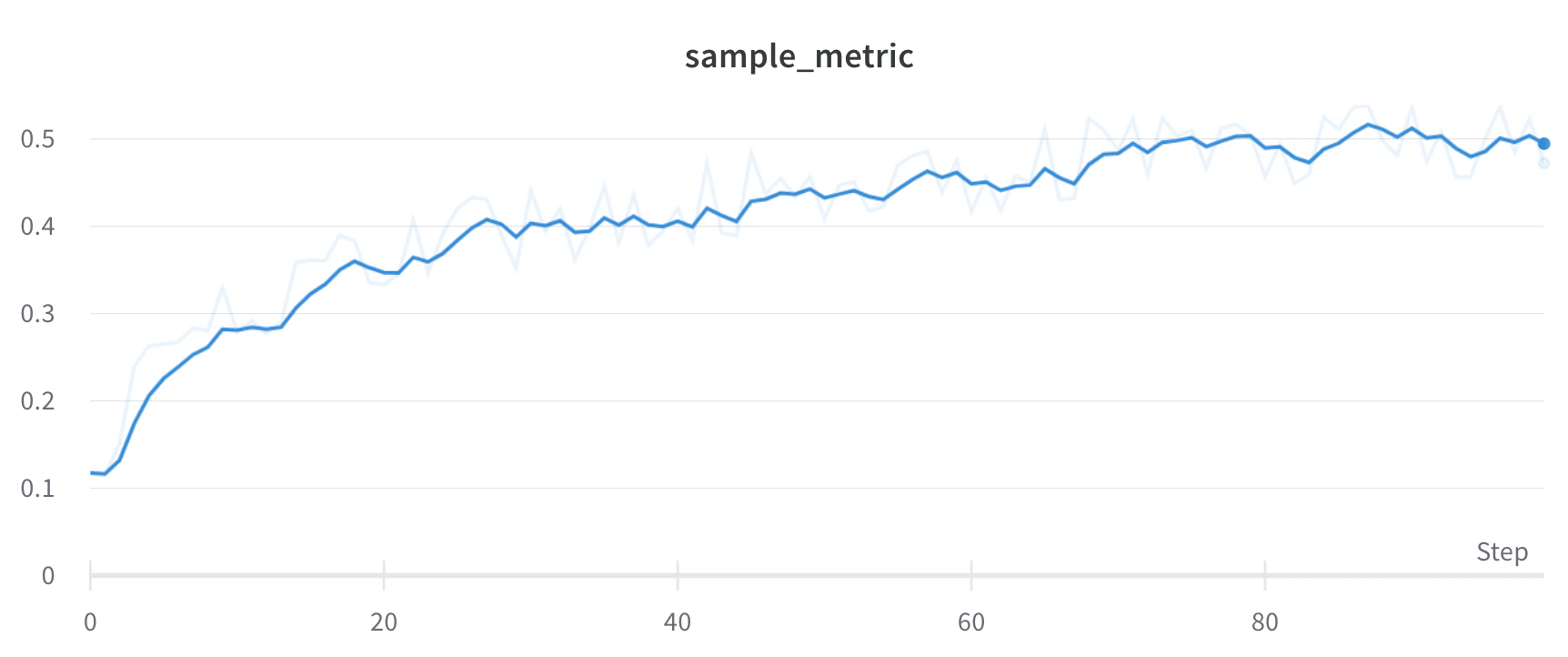
Lissage par moyenne mobile exponentielle (EMA)
- Échantillonnage
- Regroupement
- Expressions
- Axes x non monotones
- Axes x basés sur le temps
L’exemple de code suivant montre comment cela fonctionne en arrière-plan :
data.forEach(d => {
const nextVal = d;
last = last * smoothingWeight + (1 - smoothingWeight) * nextVal;
numAccum++;
debiasWeight = 1.0 - Math.pow(smoothingWeight, numAccum);
smoothedData.push(last / debiasWeight);
Masquer les données d’origine